採用深度神經網路計算的數據量通常要幾筆才足夠??
想請教一下,若有一個數值預測回歸問題, 可以用一般機器學習來解決的話, 那另外採用深度神經網路做回歸計算, 訓練出來的結果是否會比一般機器學習的效果還要好呢? 但若是要採用深度神經網路計算,主要的數據量有大概要幾筆以上才算ok呢? (好像有一些資料提及數據量過少的話不適合用神經網路計算)
回答列表
-
2021/05/31 下午 00:19Jaio贊同數:0不贊同數:0留言數:2
第二個問題不知道有沒有一個明確的答案,可能有些論文會提到要幾筆數據量以上才算OK,但是在這邊容我提出淺見,若有任何問題歡迎糾正、討論,一起進步。 我認為神經網路之所以好用就在於我們不清楚「對於未來結果的預測,哪些是重要的指標,哪些不是」,所以希望透過我們設定好(固定它的思維(超參數))的神經網路不斷的「思考(訓練)」後,告訴我們它的想法(權重),換句話說,一個我們清楚我們清楚相關性的數據,不太需要用到神經網路。 我們回到第一個問題,我認為結果會不相上下,但若使用傳統回歸或機器學習方法會更有效率及可解釋性,所以,在資料少、相關性高的數據下,傳統方法可能略勝一籌。
-
2021/06/05 下午 11:31Jeffrey贊同數:0不贊同數:0留言數:0
上傳一張sheet 提供參考, 基本上, 機器學習跟深度學習都有拿來解回歸的方案, 只是深度學習一般是用既有的網路模型的話, 要考慮權重更新的問題 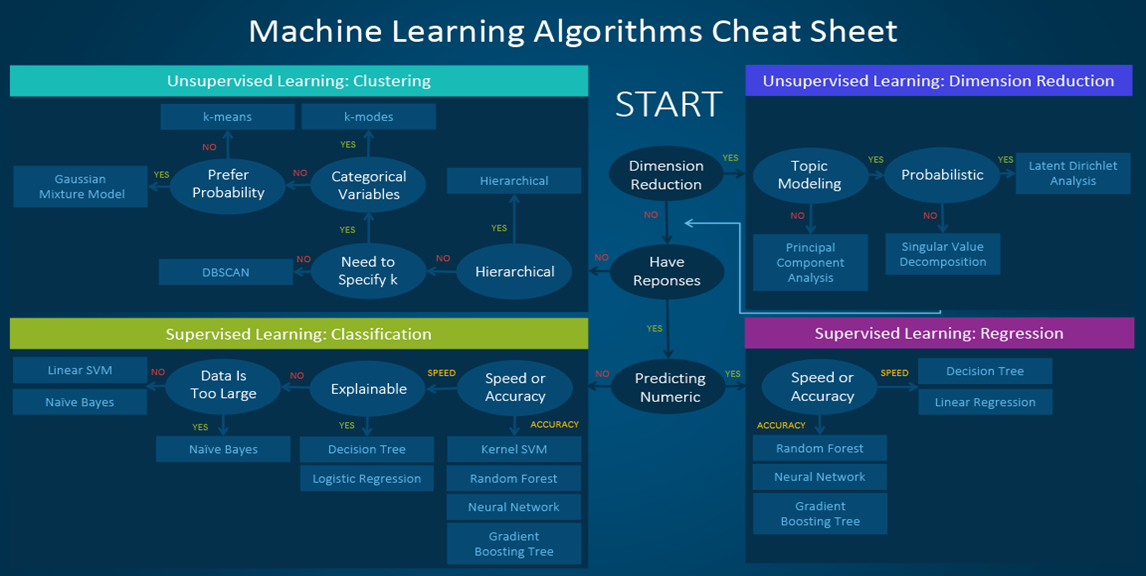
-
2021/06/06 上午 00:37張維元 (WeiYuan)贊同數:1不贊同數:0留言數:0
嗨,你好
一般來說,在大資料量小特徵數時,簡單模型如邏輯迴歸+正則即可。在小資料量多特徵下,整合的樹模型(如隨機森林和xgboost)往往優於神經網路。隨著資料量增大,兩者表現趨於接近,隨著資料量繼續上升,神經網路的優勢會逐步體現。隨著資料量上升,對模型能力的要求增加而過擬合的風險降低,神經網路的優勢終於有了用武之地而整合學習的優勢降低。我在微調:怎麼理解決策樹、xgboost能處理缺失值?而有的模型(svm)對缺失值比較敏感呢? 曾經總結過一些根據資料量選擇模型的經驗: * 資料量很小,用樸素貝葉斯、邏輯迴歸或支援向量機 * 資料量適中或者較大,用樹模型,優先 xgboost和lightgbm * 資料量較大,嘗試使用神經網路
嗨,你好,我是維元,持續在不同的平台發表對 #資料科學、 #網頁開發 或 #軟體職涯 相關的文章。如果對於內文有疑問都歡迎與我們進一步的交流,都可以追蹤 我的粉絲專頁 ヽ(●´∀`●)ノ