使用Stacking會提升模型泛化能力/魯棒性(robustness)?
我主要是對教材中的這段說明不太理解: > Q2:新的特徵,能不能再搭配模型創特徵,第三層第四層...一直下去呢? A2:可以,但是每多一層,**模型會越複雜 : 因此泛化(又稱為魯棒性)會做得更好,精準度也會下降**,所以除非第一層的單模調得很好,否則兩三層就不需要繼續往下了 以下是我對robustness和generalization的理解: > robustness *模型具有較高的精度或有效性,這也是對於機器學習中所有學習模型的基本要求 *對於模型假設出現的較小偏差,只能對演算法效能產生較小的影響 *對於模型假設出現的較大偏差,不可對演算法效能產生“災難性”的影響 > generalization *泛化能力是指學習到的模型對未知資料的預測能力 **問題點:模型越複雜 : 因此泛化(又稱為魯棒性)會做得更好? >> 模型越複雜、精度越高,泛化能力應該越差才對**
回答列表
-
2022/02/18 上午 11:46Kevin Luo贊同數:1不贊同數:0留言數:1
同學您好: 針對此問題點**:問題點:模型越複雜 : 因此泛化(又稱為魯棒性)會做得更好? >> 模型越複雜、精度越高,泛化能力應該越差才對**,替您做個回答。 我想,這是一個很精典的bias-variance 權衡的問題。 以下我幫您做小小的整理希望能幫助到你。 首先看一眼下圖:探討bias&variance和模型複雜度&Error的分析圖 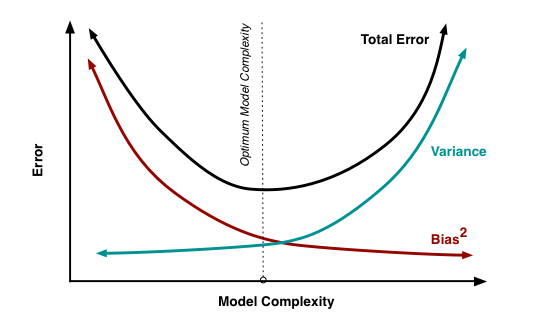 我們可以直接得到兩點: 1.我們不可能同時在bias和variance上取得最好,也就是說,超過一定複雜度之後,訓練效果好的模型,在測試時候一般會更差,因為模型會更關注訓練集中引入的雜訊,也就是出現了過擬合(overfitting)。 2.我們存在一個最優的模型複雜度,在bias和variance上取得相對最佳。 所以,我們必須在訓練和驗證的過程中找到一個"最佳複雜度的模型"。使我們Bias和Variance都保持至相對最低點。所以不一定是模型越複雜泛化能力越差,您還是得在迭代模型之performence的過程中找到一個最佳複雜度的fitting function...! 至於stacking的部分:分析一下這個方法的優缺點...和如何改善 優點:stacking的方法可以提高預測的準確度,一般情況stacking是採用兩層模型如下圖 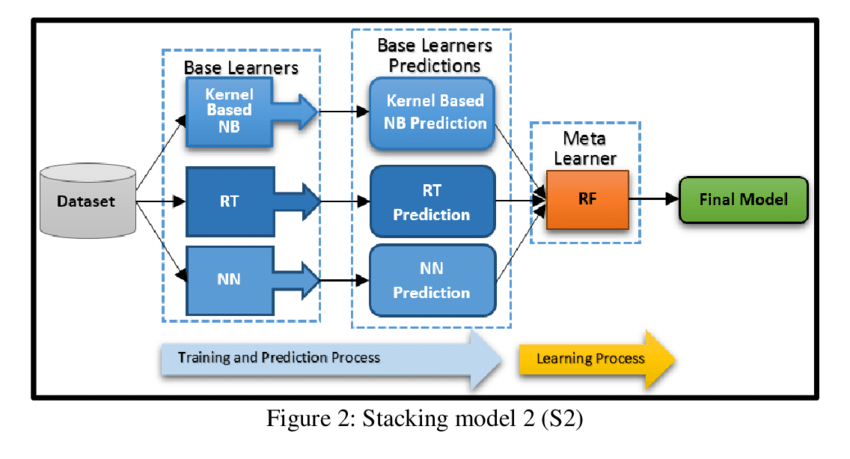 ,如果想讓它更加複雜也是可以,可以多層簡易模型,那樣就有點deep learning的感覺。 缺點:stacking是挺容易產生overfitting訓練集的,當遇到測試集和訓練集數據分佈不太一致的時候泛化能力就會不好。 改進方法? 1.最平易近人的方法是採用k折交叉驗證方法進行第一層模型的訓練和預測,交叉驗證本身訓練集有區別,可以適當提生單個模型的泛化能力。 2.小技巧,在第一層模型中,可以皆選用簡單的一些線性模型,簡單的模型複雜度不高,一般就不易產生較嚴重的overfitting。 不知道有沒有回答到您的問題?