【QA】甚麼樣基於CNN的演算法可以real-time的進行多重物件偵測/分類??
此類問題的一個基本問題之一是,我們無法應用基本的 CNN 來找出一張影像其中的一些要辨識的物件。 原因是,當一個圖像有多重標籤時,傳統的 CNN往往容易被混淆。 這也是 CNN 無法真正弄清楚這是區分圖像中特定對象的獨特因素。 例如,在一個給定的圖像中,有一個香蕉和一顆橘子。 然而,傳統的 CNN 無法真正理解圖像中的香蕉或橘子究竟是什麼。 CNN 可能最終會學習說圖像中是否有購物袋,而不是橘子和香蕉。 因為大多數帶有香蕉和橘子標籤的圖像往往都有一個購物袋或固定的顏色在image中。 話至此,我想現在您應該很清楚我們不能真正使用 CNN 來解決很多真實世界問題的原因吧? 那我們還有甚麼更好的方法嗎?
回答列表
-
2021/11/23 下午 11:45Kevin Luo贊同數:0不贊同數:0留言數:0
很好地使用帶有一些調整算法的 CNN。 圖像中多對象分類的傳統方法是使用物件檢測(object-detection)算法並在此基礎上運行 CNN。 因此,您可以使用滑動窗口(sliding windows)或其他任何更先進的物件檢測算法,並找出感興趣對象所在的位置。 例如,找出每個圖像上的邊界框(綠色or紅色or更多顏色的框框)。 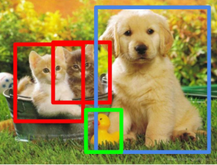 這些邊界框將包含圖像中感興趣的對象,例如蘋果、貓、橙子、香蕉等。一旦你弄清楚這些邊界框,你就可以在對象檢測器的頂部運行傳統的 CNN 並將這些綁定框傳遞給你的網絡做物件分類。 並最終將圖像的所有分離部分組合起來形成整個完整圖像以提供結果。 R-CNN RCNN即Region CNN,可以說是利用深度學習進行目標物件檢測的開山之作,它用CNN(AlexNet)代替了之前sliding window的方法。 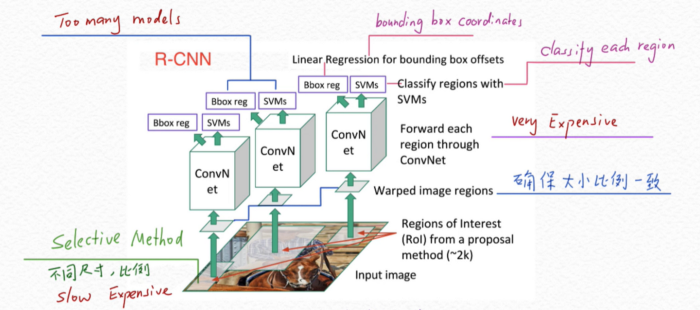 上圖顯示了 R-CNN 的運行概念。 首先我們通過Selective Search(選擇性搜索)去生成大量的認為可能存在目標物體的小圖塊。 然後將所有的這些圖塊通過預訓練得很完美的CNN進行特徵提取,比如AlexNet、VGG等pre-trained model。 然後我們再對這些convNet卷積網路的輸出進行兩個操作:(1)Bbox Regression,確定Bbox框出的目標位置,即用回歸的方式確定Bbox的4個parameters;(2)分類,即用SVM判斷Bbox標註的目標是什麼物體。 R-CNN的主要缺點就是計算成本非常巨大,這裡會用上千張小圖塊去通過一個同樣的卷積網路,即進行約2000次左右的串行式前向傳播,而在之後又要分別經過回歸和支援向量機兩個模型,也就是要重複地執行以上操作上千回,導致嚴重影響了計算速度。 由於使用了AlexNet(或者VGG),需要每一個候選框統一成相同的227x227(pixel)的尺寸(若使用VGG,則是224x224),這就嚴重影響了CNN提取特徵的品質。 由於R-CNN中SVM需要單獨訓練,隨著類別的增加訓練SVM的個數也會增加,這也使得訓練過程更加複雜。 此外,Selective Search去生成這些圖像塊的過程也是非常成本昂貴和緩慢。 總結R-CNN 有什麼問題 (1) 諸如具有特定步伐的滑動窗口之類的CNN算法在大型圖像上運行速度極慢。 即使是選擇性搜索和更快的對象檢測變體等算法也非常緩慢。 RCNN 通常提取出大約2000個區域,CNN 將在這些區域中的每一個上運行並提取高級特徵來進行分類。 而這些區域提案往往非常緩慢。 (2) 事實上,即使我們提出了區域,每張圖像也需要好幾秒的時間來進行分類並將其重新組合在一起。 (3) 我們需要多階段訓練才能運行此模型。 我們需要訓練目標檢測器算法,用CNN 來提取高級特徵,以及另一種算法來進行分類。 我這邊不會詳細介紹,如果各位想看詳細介紹,請閱讀此篇論文。 我這篇只是解決方案的一些概述。 那麼我們如何克服這個問題呢? 其實很簡單,只需稍微調整我們的pipeline,它就會加快它的運算流程。 只需將 CNN 放在開頭,目標物件提案放在結尾。 然後SVM或者其他算法來做分類。 因此,首先用CNN提取高級特徵,在其上運行物件檢測以提出區域,然後最後進行分類。 這個被修改的過程後來被統稱為 Fast-RCNN,這是由微軟(Microsoft)所提出的方法。 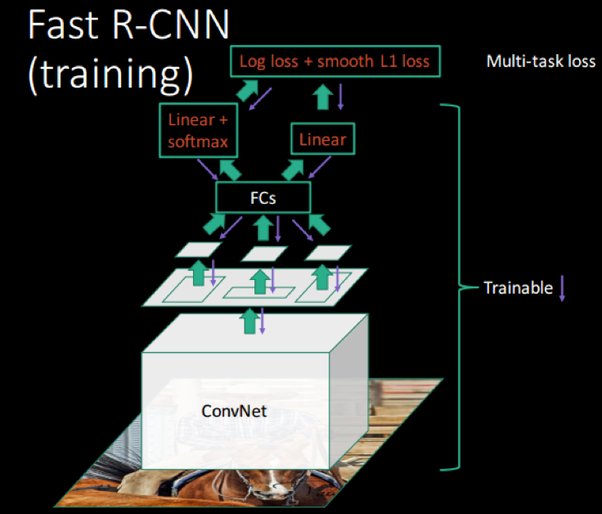 上圖描述了 Fast-RCNN 的工作原理。 Fast-RCNN的優勢 更快的訓練時間。 訓練速度比 RCNN 快 8.8 倍。 那麼Fast-RCNN有什麼問題呢? 做region proposal仍然需要2秒左右,在測試的時候是個瓶頸。 而這些對於實際應用來說是不現實的。 [閱讀此篇Fast R-CNN論文來獲取更多資訊](https://arxiv.org/abs/1504.08083) 那麼解決方案是什麼? 那麼上面兩個算法的問題都是物件檢測,這些算法非常慢…。 有沒有辦法加速這些算法? 對此的簡單解決方案是訓練 RPN(區域提議網絡),這是一種挺複雜的物件檢測神經網絡,並最終將其傳遞給 CNN 進行分類。 架構中會分成兩個 CNN,一個純粹做物件檢測,另一個純粹做分類。此方法被稱為 Faster-RCNN。 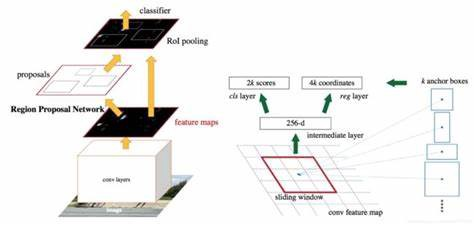 上圖說明了 Faster-rcnn 的工作原理。 Faster RCNN可以分為4個主要部分: 1.conv layers 作為一種CNN網路目標檢測方法,Faster RCNN首先使用一組基礎的convolutional卷積+relu激活函數+pooling池化提取image的feature maps。 該feature maps被共用用於後續RPN層和全連接層。 2.Region Proposal Network RPN網路用於生成region proposals。 該層通過softmax判斷anchors屬於positive或者negative,再利用bounding box regression修正anchors獲得精確的proposals。 3.RoI pooling RoI即Region of Interest,RoI pooling是池化層的一種。該層收集输入的feature maps和proposals,综合這些訊息後,提取proposal feature maps,送入後續全連接層判定目標物件的類別。 4.classifier 利用proposal feature maps計算proposal的類別,即確定是什麼物體。 同時再次進行bounding box regression以獲得檢測框最終的精確位置。 Faster-RCNN 的優勢 在訓練和測試時間加速大約是R-CNN的250 倍。 可以使用於真實世界的任務。 [更多Faster R-CNN的資訊請詳參此論文](https://arxiv.org/abs/1506.01497)