【QA】甚麼是聯邦式學習(Federated Learning)?
回答列表
-
2021/11/23 下午 11:38Kevin Luo贊同數:0不贊同數:0留言數:0
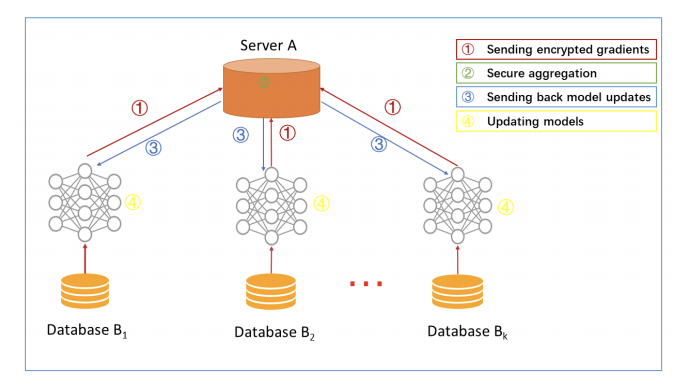
什麼是聯邦式學習? 通過分散式優化、隱私研究和機器學習的結合,聯邦式學習因而誕生了。 說到分散式計算和徹底加密的隱私性保障,就不得不提到一個技術 — 區塊鍊。 區塊鍊的技術現在廣泛運用於電子加密貨幣,透過每一個自願者電腦的計算能力串出一長串的區塊(分散式系統),然後最後每一個區塊串接在一起。每個人都可以無時無刻的察看其交易內容(透明化交易),但又有公鑰和私鑰在做隱私的保障,私鑰的密碼有2^256種可能性,且每十分鐘變換一次,要破解區塊鍊下的加密貨幣幾乎是不可能的事。 所以說到聯邦式學習可以想說它是機器學習界的加密貨幣。分散式系統且難以破解的資料串接且共同訓練。 維基百科的正式定義: 聯邦式學習(也稱為協作學習)是一種機器學習技術,它訓練演算法跨越多個分散的邊緣設備(Edge Device)或伺服器保存本地數據樣本,而無需交換它們。 這裡的關鍵字是分散式( decentralized)和本地資料。 Centralized ML 走向 Federated Learning: Centralized ML: 在訓練過程中將 Data 上傳,在數據中心做訓練和推理,將結果發送給使用者:數據上傳具有隱私和安全風險;時延過高;浪費終端設備的算力。 Distributed On-Site Learning: 雲端將模型發送給各終端,終端根據本地數據對模型進行訓練和推理:數據量少,無法從其他用戶數據獲得提升。 Federated Learning (FL):每個設備訓練模型並將參數發送到 Server 端進行聚合。 資料僅儲存在本地裝置上,透過 global model 提升性能[1] 。 FL 保證數據不離開本地,同時也充分利用的終端設備的算力,減輕了 Server 端的計算成本和數據存儲量。 Google人工智慧研究人員在2016年發表的一篇論文中介紹了這一點:Communication-Efficient Learning of Deep Networks from Decentralized Data. 聯邦式學習背後的主要理念是將集中模式引入分散式設備做計算和訓練( centralized model to the decentralized edge devices),從而無需獲取用戶數據。下面補充一下甚麼是分散式計算和訓練。 什麼是分散式計算? 分散式系統是一組電腦,透過網路相互連接傳遞消息與通信後並協調它們的行為而形成的系統。 元件之間彼此進行交互以實現一個共同的目標。 把需要進行大量計算的工程數據分割成小塊,由多台計算器單位分別計算,再上傳運算結果後,將結果統一合併得出數據結論的科學。 分散式系統的例子來自有所不同的面向服務的架構,大型多人在線遊戲,對等網路應用。 什麼是分散式訓練? 分散式機器學習(or深度學習)領域涉及內容廣泛,在學術上包含演算法設計、理論證明等問題,在工業應用上涉及系統設計、產品研發等工作。 此篇僅從學術角度方面,站在系統的角度來介紹分散式訓練的相關知識。 單機環境下會遇到一些問題,例如模型複雜導致GPU放不下,數據量太大無法載入,所以需要進行分散式訓練。 而在線上真實生產環境下,後端系統一般採用分散式架構運行在集群中,這裡涉及到資源的調度、負載均衡、快速擴展、滾動更新等問題。 由於用戶端的數據不會離開其Edge device,這有助於保留數據的隱私性和保障數據安全,只有最終的模型是被分享的(這部分待會再提)。 這種機器學習的隱私性升級是具有革命性的,為機器學習應用程式處理敏感且隱私的數據開闢了新的道路。 但是,在我們深入探討聯邦式學習的應用例子和益處之前,讓我們先來瞭解它如何work的。 工作原理 我們將以Google的Gboard的下一個單詞預測器為例,並逐步完成聯邦式學習的過程。 補充: (Gboard(Google鍵盤)是Google為Android和iOS裝置開發的輸入法程序,提供滑行輸入及語音輸入等功能,并支援輸入三百余種語言。) 首先,Google 在其雲伺服器中構建了一個基礎 ML 模型,該模型經過公共數據訓練。 然後,幾個使用者設備自願訓練模型。他們通過下載模型時連接到電源和wi-Fi網路(因為訓練模型是一個密集的操作,我們不想耗盡使用者設備的電力)。 他們為模型提供相關數據- 點擊日誌、預測反饋等,以便模型學習和改進。 完成訓練後,對模型的任何更新或改進都進行彙總和加密且發送到雲端中,用新的資訊更新基礎模型。 這種下載和更新週期發生在多個設備上,在達到良好精度之前不段重複。只有這樣,模型才會分發給其他使用者,用於所有類型的用例。 需要注意的是,訓練數據仍會保留在用戶的地端設備上:只有訓練結果被加密並發送到雲端中。 下面是其詳細過程圖示: 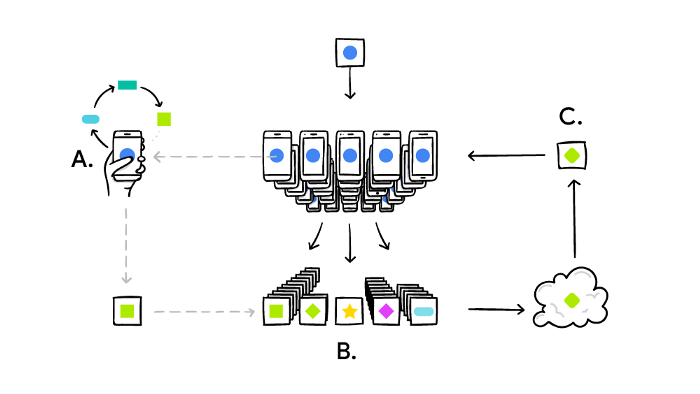 您的手機會根據您的使用方式個人化本地的模型(A)。許多使用者的更新被匯總(B)以形成對共用模型的一致更改 (C),之後重複迭代這個過程。 這種訓練和開發機器學習模型的協作方式非常強大,且具有真實世界的應用性。 應用場景 如果由於法律、經濟、道德…等原因而孤立數據,聯邦式學習將會大放異彩,因為它允許獨立方在更大的數據集上訓練他們的模型。 1. 醫療保健 一個很好的例子是數位醫療。由於患者的隱私和數據管理,醫療機構的數據總是被隔離的,未經患者同意一概不得使用。基於傳統方法,機器學習模型只能從很有限的可用開源數據源中訓練、學習,並且偏頗於醫院的儀器/人口統計學/實踐。 通過聯邦式學習,AI 演算法可以從其他醫院獲得更多資訊,捕獲更多公正的資訊,如性別、年齡、人口統計學等,這些資訊可以説明模型做出更通用(more generalization)的預測。 更多資訊→數位健康的未來與聯合學習 2. 自駕電動車 自動駕駛電動車也可以被視為單個參與者( individual actors),只是學習場景被帶到自駕車上,而不是將數據發送回中央伺服器。 由於在現實世界中駕駛是充滿危險性的,而且往往不可預知,聯邦式學習可以加速其學習過程,減少傳輸大量數據的需要。最終,它有可能加快全自動駕駛的進程。 聯邦式學習的應用更多,主要在物聯網 (IoT) 領域,它與相同的資訊相呼應,即在維護數據隱私和減少高通信和存儲開銷的同時,利用 ML 實現物聯網。 一些限制和挑戰 聯邦式學習仍然是一個相當新穎的想法,一些普遍的限制和挑戰,阻止了它充分發揮其潛力。 1. Non-iid data 在傳統機器學習中,數據分佈在同一個機器上,並且假設數據是從同一個分佈中獨立採樣的,即數據獨立同分佈(Independently Identically Distribution, IID)。 後來隨著數據量的急劇暴長,大數據時代需要分散式演算法進行並行計算,此時分散式優化(Distributed Optimization)主要做的事情是利用多台機器對大數據或者大模型進行並行計算,包括模型並行(Model Parallelism)和數據並行(Data Parallelism)兩種基本範式。 但此時仍只是為了加速計算,各個用戶端上的數據仍然是IID的。 但是隨著物聯網(Internet of Things, IoT)設備的大規模使用,如何協同數以萬計的設備及其私有數據進行訓練模型則是聯邦學習做的事情,此時由於設備歸屬於某個使用者、企業、場景,因此其數據分佈往往是差異極其大的,即數據非獨立同分佈(Non-IID)。 第一,非同分佈很容易理解,就是因為數據分佈差異大;其次,由於受到用戶群體、地域關聯等因素,這些設備的數據分佈往往又是有關聯的,即非獨立。 2. 設備計算能力 參與聯網的每個設備在軟體和硬體級別(網路連接、RAM、電源等)上的能力各不相同。雖然當今大多數智慧手機都能夠執行計算密集型任務,如訓練模型,但仍有很大一部分邊緣設備無法執行訓練工作,並且會降低設備的性能。在保持設備性能和模型精度之間會必須有一個權衡(trade-off)。 3. 資料標記 許多監督式的 ML 技術需要清晰和一致的標籤才能執行該演算法。由於數據來自各種設備,必須實現良好的數據管道才能自動標記數據。 4. 數據洩漏 通過逆向工程技術,仍然可以識別和從特定用戶獲取數據。然而,隱私技術,如差異隱私可以加強聯邦學習的隱私,但代價是可能會降低模型的準確性。 結論: 聯邦學習是人工智慧中的一個強有力的理念。它允許在低延遲和低功耗下分散多台edge設備學習,同時確保數據私密和安全。 但在現實世界中實際應用之前,它仍然面臨著挑戰,但現今持續進行大量的研究。 我希望此QA能激發你對聯邦式學習的興趣,讓你一窺它是什麼,它能取得什麼成就。 References: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html https://venturebeat.com/2021/08/13/what-is-federated-learning/