【QA】為什麼在訓練模型時要做提前停止(early stopping)?
early stopping是模型正則化的一種方法。可以有效地節省整個AI的訓練時間
回答列表
-
2021/11/12 下午 01:44Kevin Luo贊同數:0不贊同數:0留言數:0
當訓練具有足夠表徵配適能力能力的大型模型而過度配適(Overfitting)時,往往觀測到訓練誤差隨著時間遞減,而驗證集(Validation set)誤差再次開始上升。對於此行為的範例,可參考下圖(稱它圖1),這樣的behavior的確是會發生的。 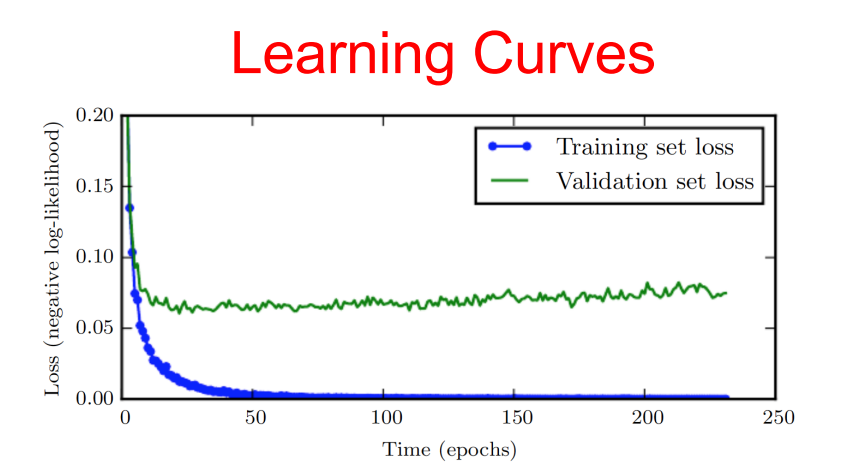 圖1: 此學習曲線顯示負對數概似隨時間變化的程度(表示為資料集或回合(Epochs-訓練的迭代次數)。 範例中,在MNIST資料集上訓練maxout網路。觀測訓練目標隨著時間遞減,但驗證集的平均損失最終卻又再次開始增加,形成一個不對稱的U型曲線。 那這意味者什麼? 意味者可以透過在最低的驗證集誤差的次數點回到參數設定,從中獲得具有較佳驗證集誤差(因此希望更好的測試集誤差)的模型。每次驗證集的誤差改進時,都會儲存模型參數中的副本。當訓練演算法終止時,傳回這些參數(而非最新的參數)。 在某些預定迭代次數中,對最佳紀錄的驗證誤差沒有任何參數改進時,則此演算法將終止。 此程序在以下演算法中將有更正式的描述。(圖2) 確定最佳訓練次數的提前停止共通式演算法(meta-algorithm 元演算法)。 此共通式演算法是一種通用策略,可以與各種訓練演算法以及驗證集的誤差量化方式妥善配合使用。  解說上面的元演算法: 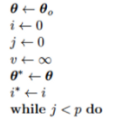 令n為運算之間的步數。 令p表”耐力”,即放棄運作前對惡化的驗證集誤差觀測的次數。 令θ0(0為下標)為初始參數。  執行訓練演算法n步以更新θ。 最後最佳解為θ star,而最佳訓練步數為i star。 這種策略稱之為提前停止(early stopping)。其可能是深度學習中最常使用的正則化(Regularization)形式。之所以熱門因為其簡單且有效。 可將提前停止方程式視為非常有效的超參數選擇演算法。以此觀點,訓練步數只是另外一個超參數(hyperparameter)。 如上面圖1所示,此超參數具有U形驗證集效能曲線。 控制模型配適能力的大多數超參數具有U形驗證效能曲線,如下圖圖3所示: 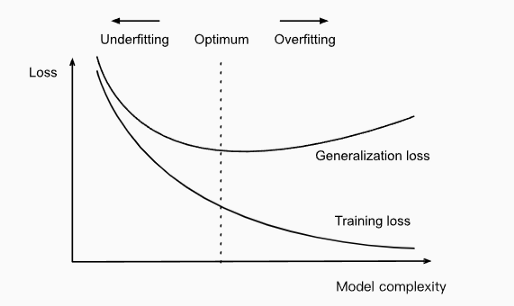 在提前停止的情況下,藉由決定配適訓練集所採取的步數,以控制模型的有效配適能力。許多hyperparameters的抉擇必須使用成本高昂的猜測和檢查過程,其中在開始訓練時設定某個超參數,並執行訓練數個步驟以查看效果。 "訓練次數"超參數的獨特之處在於,根據定義,單一回合的訓練可以試用此超參數的許多值。採用提前停止,自動選擇超參數的唯一主要成本是,訓練期間定期執行驗證集的計算。理想情況上,此訓練過程可在與主訓練過程分離的單獨機器, 單獨CPU或單獨GPU上平行完成。若無這樣的資源可用,則可以使用比訓練集小的驗證集,或藉由較不頻繁的計算驗證集誤差,以及獲得較低解析的最佳訓練估計,以降低這些定期計算成本。 提前停止的額外成本是需要維護最佳參數的副本,此成本通常微不足道,因為可以將這些參數儲存到較慢與較大的記憶體裝置中(比如說在GPU中訓練,然後將訓練後的最佳化參數儲存至主機的記憶體或hard drive中。)由於很少將最佳化參數寫入且訓練期間不需讀取,所以這些偶爾為之的緩慢寫入,對於訓練總時間的影響是很些微的。 提前停止(early stopping)算是一種較不顯眼的正則化(Regularization)形式,因其所需的潛在訓練程序, 目標函數或一組容許參數值幾乎無變更。這意味著在不損害學習動態下即可輕易採取提前停止。 這與權重衰減形成對比,在權重衰減中,必須小心更新,不要使用過多的權重衰減,進而將網路陷於不好的區域最小值,導致對應具有病態小權重的解。而提前停止不會。 提前停止可以單獨使用,也可以與其他正則化(Regularization)策略一同使用。即使用正則化策略修改目標函數以促進更佳的泛化(generalization),而最佳的泛化也很少出現在訓練目標的區域最小值處。 總結一下Early stopping: 優點: 節省可觀的訓練時間,並且保持效能 首先將一小部分訓練集作為我們的驗證集, 每一個epoch結束時,計算驗證集的accuracy 一旦我們發現驗證集上性能越來越差, 但驗證性能卻超過了我們預先設定的值(下圖虛線發生的時間點), 可能就是發生overfitting,就立馬終止訓練過程。 **這樣就不會傻傻的一直overfit下去,可節省很多等待的時間。** 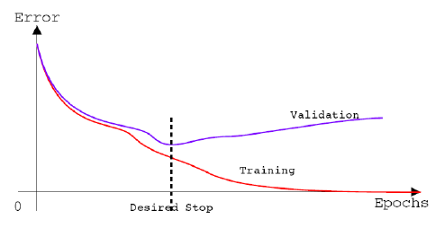 Pytorch的early stopping程式參考資料:https://clay-atlas.com/blog/2020/09/29/pytorch-cn-early-stopping-code/ Reference: 1.https://d2l.ai/chapter_multilayer-perceptrons/underfit-overfit.html 2.https://www.researchgate.net/figure/The-early-stopping-criterion_fig2_4310358