在文字的特徵擷取中,TF-IDF是什麼?
在NLP領域中,表示一個字或一個詞的方法很多,而TF-IDF是用來表現一個字詞最常見的特徵,特別在文本分類中常使用。具體來說,TF-IDF的含意是什麼呢?
回答列表
-
2021/11/10 下午 06:14王健安贊同數:0不贊同數:0留言數:0
TF-IDF是一種針對字或詞的加權數值,當某個字或某個詞彙在某一文本中出現次數多,且出現在其他文本的次數少,代表它是該文本的重點或主要資訊。 TF-IDF包含兩個部分:TF (Text Frequency)以及IDF (Inverse Document Frequency)。 TF用來計算某個字或詞彙在所有文本中出現的次數,公式如下: 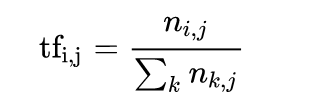 其中n_(i, j)是指某個文字 i 在某個文本 j 中出現的次數、n_(k, j)則是某個文本 j 所有詞彙的數量。 IDF則是計算「log( 總文件數量 / 包含該詞彙的文件數量 )」,主要目的在於求出某個詞彙在其他文本出現的頻率。 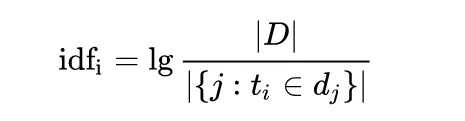 綜上所上,TF-IDF會等於: 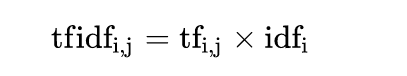 在python操作方面, 可善用sklearn package中的 TfidfVectorizer實現TF-IDF的計算。 參考資料: - [ ] [NLP] 文字探勘中的 TF-IDF 技術 https://clay-atlas.com/blog/2020/08/01/nlp-%E6%96%87%E5%AD%97%E6%8E%A2%E5%8B%98%E4%B8%AD%E7%9A%84-tf-idf-%E6%8A%80%E8%A1%93/ - [ ] NLP基本方法:TF-IDF原理及應用 https://iter01.com/189491.html - [ ] TensorFlow與NLP(TF-IDF:垃圾簡訊檢測) https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/468440/ - [ ] Introduction to NLP - Part 3: TF-IDF explained https://towardsdatascience.com/introduction-to-nlp-part-3-tf-idf-explained-cedb1fc1f7dc