【QA】為什麼使用Relu能夠解決梯度消失?
Relu是一個在深度學習中常被使用到的激活函數,本次想要與各位探討一下Relu為何能夠有效的解決梯度消失的問題
回答列表
-
2021/09/03 下午 03:40Ray贊同數:0不贊同數:0留言數:0
梯度消失通常發生在使用了不恰當的激活函數,如:sigmoid,或是深層網路當中; Sigmoid 雖然作為激活函數是一個平滑便於求導數的函數且能壓縮資料到0-1之間,但是卻有梯度消失的問題,也因此衍生出了 Rectified Linear Unit ( ReLU ) 這樣的 activation function。 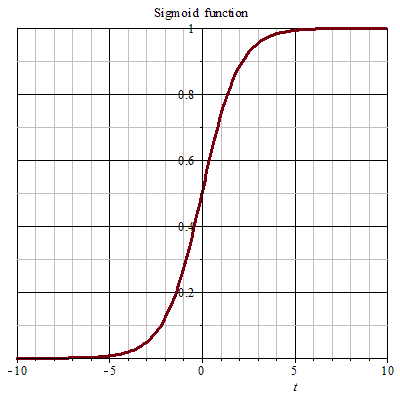[參考圖片來源](https://zh.wikipedia.org/wiki/S%E5%87%BD%E6%95%B0) Sigmoid的導數曲線如下圖: 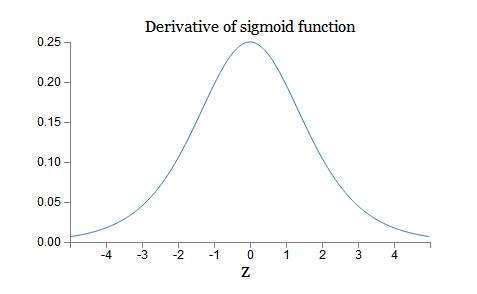[參考圖片來源](https://www.google.com/url?sa=i&url=https%3A%2F%2Fblog.csdn.net%2Fqq_21190081%2Farticle%2Fdetails%2F64127103&psig=AOvVaw1PeihbRQu1FMZdayicglBT&ust=1630741094558000&source=images&cd=vfe&ved=0CAsQjRxqFwoTCJjzzpCm4vICFQAAAAAdAAAAABAD) 從圖中可以發現,sigmoid導數的閾值是(0, 1/4),導致神經網絡在反向傳播的時候,其梯度越來越小,最後甚至根本無法訓練;而與之相比,relu的導數曲線如下: 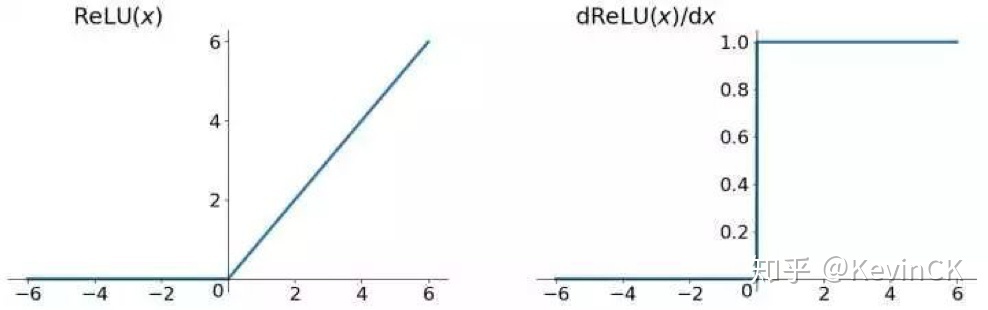[參考圖片來源](https://www.google.com/url?sa=i&url=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F73214810&psig=AOvVaw26Q94XZcfYBT40w5lHTkFc&ust=1630741002445000&source=images&cd=vfe&ved=0CAsQjRxqFwoTCIijpual4vICFQAAAAAdAAAAABAD) 相較於sigmoid的導數只有在0附近的時候有比較好的激活性,在正負飽和區的其值都十分接近於0,relu函數在輸入值大於0的時候其值皆為1,這也代表著當輸入值為正數時不用擔心梯度消失的問題,而relu函數在輸入為負數時其導數為0 ,也就代表著神經元不會被激活,使得整個神經網路變得更輕巧、更多樣性,但卻不會使梯度變得越來越小,但是這也產生了另一個相應的問題,也就是dead relu probelm,當輸入值小於0时,梯度為0。這個神經元及之後的神經元梯度永遠為0,神經元不再對任何數據有所反應,導致相應參數永遠不會被更新。 爲解決這個問題,後續又產生了Leaky Relu以及PRelu(Parametric ReLU)這兩個激活函數,其各自的特點如下: **_Leaky ReLu_**:ReLU在input小于0时,output为0,这时微分为0,你就没有办法updata你的参数,所有我们就希望在input小于0时,output有一点的值(input小于0时,output等于0.01乘以input),这被叫做leaky ReLU。 **_PRelu(Parametric ReLU)_**:在input小於0時,output等於alpha為neural的一個參數,可以通過training data學習出來,甚至每個neural都可以有不同的alpha值。 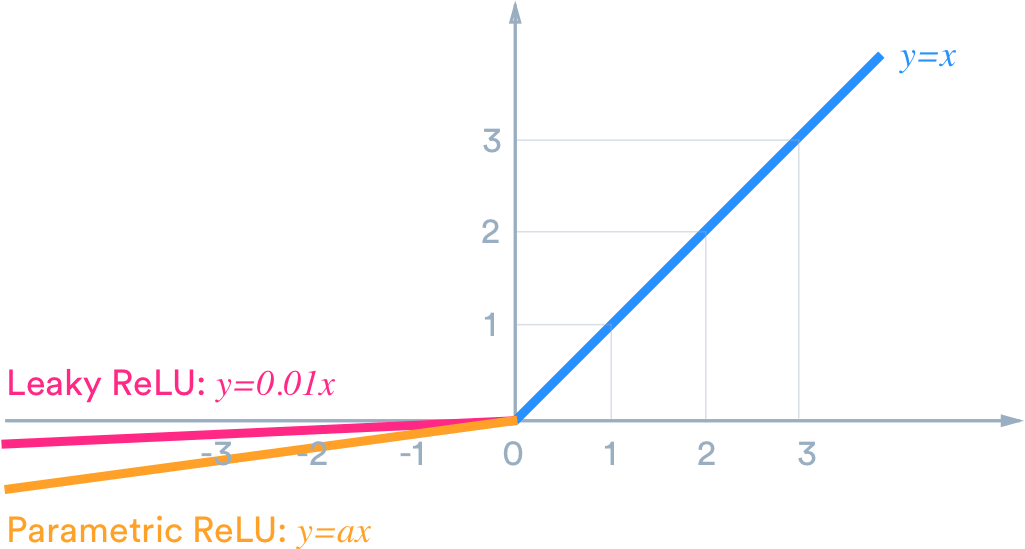[參考圖片來源](https://www.google.com/url?sa=i&url=https%3A%2F%2Fhimanshuxd.medium.com%2Factivation-functions-sigmoid-relu-leaky-relu-and-softmax-basics-for-neural-networks-and-deep-8d9c70eed91e&psig=AOvVaw0-SJrb6-xBy5psxZXQ3wAF&ust=1630740631752000&source=images&cd=vfe&ved=0CAsQjRxqFwoTCIC04rOk4vICFQAAAAAdAAAAABAD) > 除此之外還有其他解決梯度消失的方法,有興趣的話可參考該[連結](https://datawhalechina.github.io/leeml-notes/#/chapter18/chapter18?id=%e6%a2%af%e5%ba%a6%e6%b6%88%e5%a4%b1)