【QA】常見的優化器(optimizer)方法有哪些?
Optimizer最主要的功用就是幫助神經網路調整參數,我們得知Loss 後,透過優化器,來調整模型,使得Loss越小越好。 而神經網路用的優化器種類也是相當多元,下面簡單介紹一下各種優化器的特性,以及個優化器的優缺點。
回答列表
-
2021/08/18 上午 00:06Chili贊同數:0不贊同數:0留言數:0
* SGD ( Stochastic Gradient Descent): SGD就是最基本梯度下降的方法,利用一階微分的概念找出參數梯度,並依據梯度方向做更新。  --- * Momentum: 這個優化器就是將物理動量的概念帶到神經網路中,在同方向的維度的學習速度較快,不同方向的學習速度較慢。 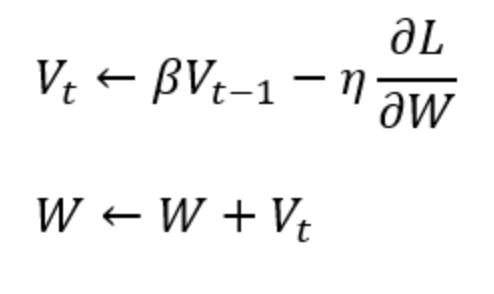 當Vt 參數跟上一次同方向時,更新梯度便會變快,如果方向不同Vt會變小。 --- * AdaGrad: 與前面幾種固定學習率(Learning rate)的優化器不同,AdaGrad即為依照梯度大小調整學習率(Learning rate)的優化器。 (若學習率太大會造成Overfitting ;太小會需要更多時間學習) 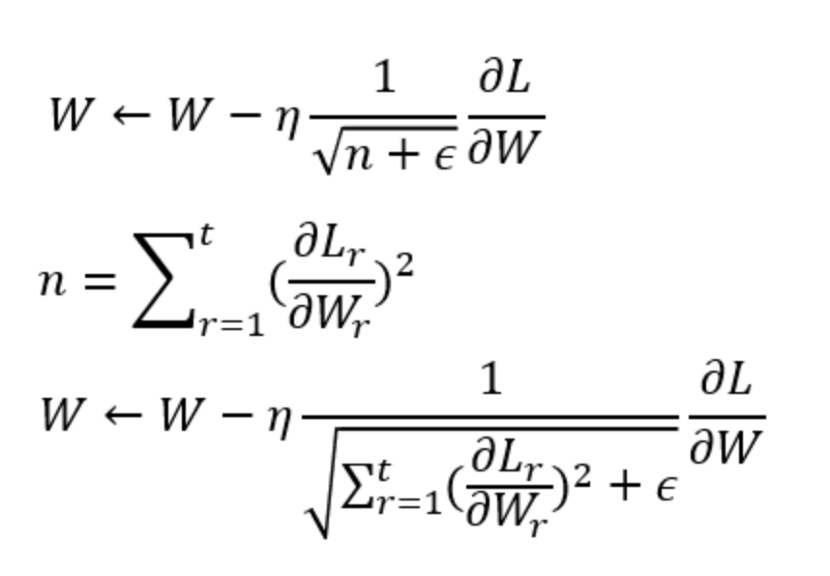 *當梯度小時,會放大學習率,加速學習 *當梯度大時,則會約束學習率 --- * ADAM: 結合前面介紹的Mometum&AdaGrad,也是目前常用的優化器。 對梯度方向做速度調整,也會針對梯度平方值做學習率上的調整。 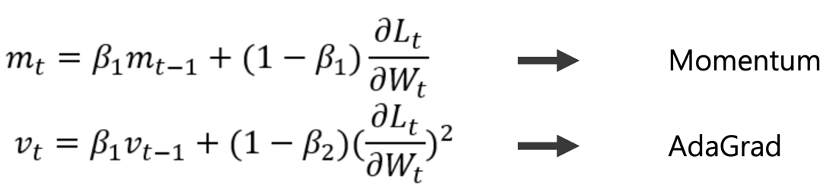 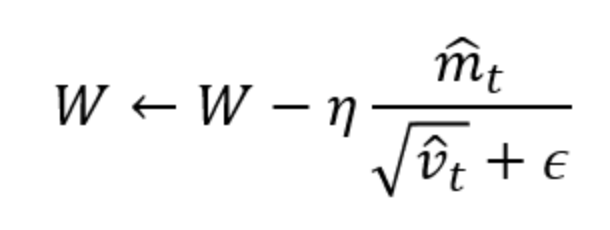 --- * 優化器特點比較: 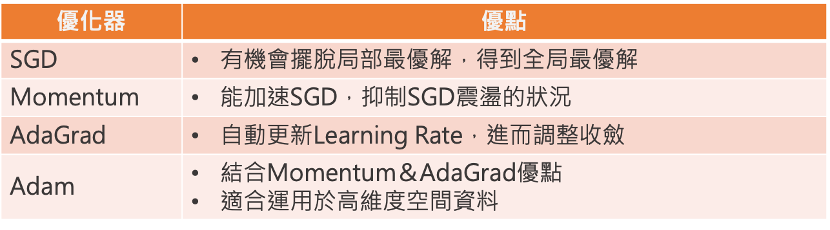  --- - 參考答案來源: 莫煩: https://www.youtube.com/watch?v=UlUGGB7akfE&list=PLXO45tsB95cJ0U2DKySDmhRqQI9IaGxck&index=17 https://medium.com/雞雞與兔兔的工程世界/機器學習ml-note-sgd-momentum-adagrad-adam-optimizer-f20568c968db