【QA】在CNN中的池化層的使用上為何較多使用Max-Pooling??
在CNN中,除了卷積以外還有一個重要到概念,也就是池化(pooling),一般來說在卷積層後面都會接上池化層,池化層主要有兩種:最大池化層(Max-pooling)與平均池化層(Average-pooling) 現在大多使用最大池化層(Max-pooling),為什麼? 以下想跟各位討論一下
回答列表
-
2021/08/14 下午 07:48Ray贊同數:0不贊同數:0留言數:0
池化層的作用是將輸入的數據進行壓縮以減少參數量,在減少feature map維度的同時保留重要的特徵,用在影像處理方面的話就是圖像的縮放,如下圖  雖然圖像被壓縮變小了,但是並不影響我們對於圖像的辨識,這個概念有點類似PCA主成份分析,簡而言之池化層就是對圖像進行降維, 池化層的特點如下: 1. 減少後續全連接層所需要計算的參數量,減輕運算負擔:以最大池化層為例,輸入的圖片經 過池化窗口為2x2、Stride(步長)為2的pooling kernel之後,整個圖片的尺寸將會縮小為原本 的1/2,參數量則會降低至原本的25%,同時因為減少了參數量,在控制過擬和、增加模型的 泛化能力方面也起了一定的效果。 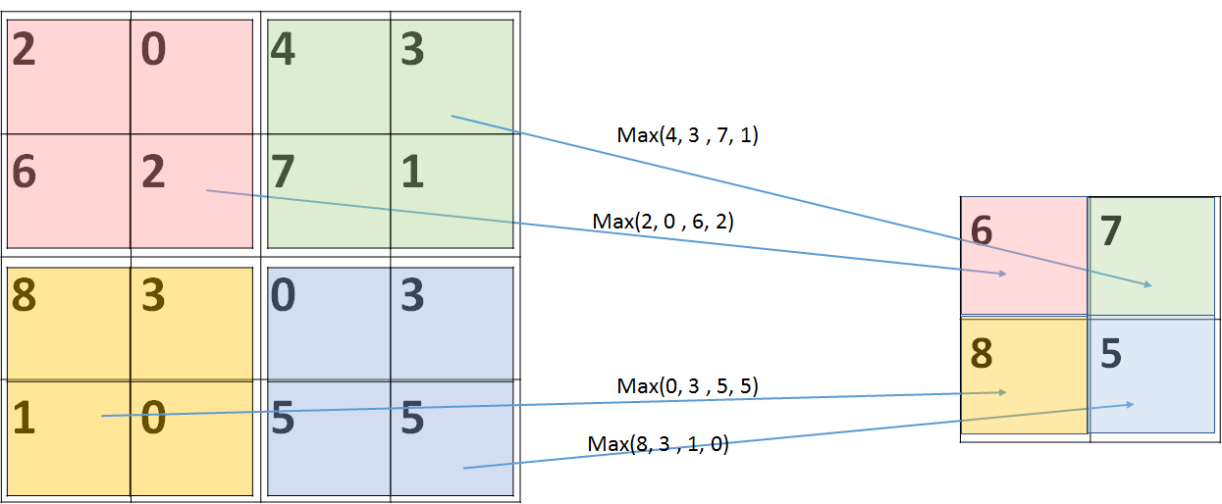 2. 特徵不變性:對於神經網路來說,一個特徵的精確位置遠不及該特徵相對於其他特徵的粗略 位置來的重要,就如同我們在上文所提及的,一張圖片被縮小後我們依舊能夠辨認該圖片, 表示該相片在經過壓縮後依然保留著最重要的特徵,從下圖來看,在經過池化壓縮後,這些 特徵的feature map依舊會是相同的 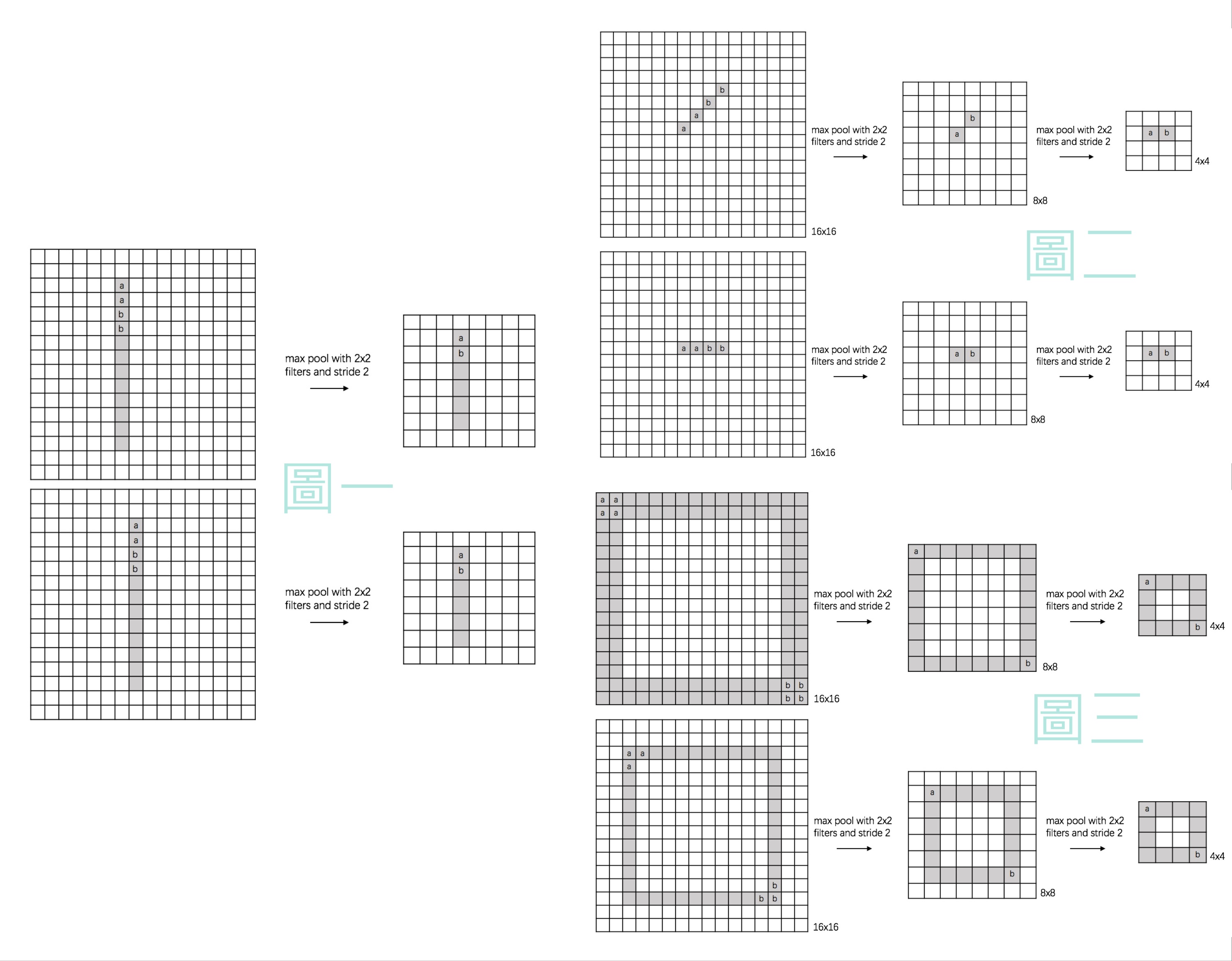 而最大池化層(Max-pooling)與平均池化層(Average-pooling)的差異如下圖 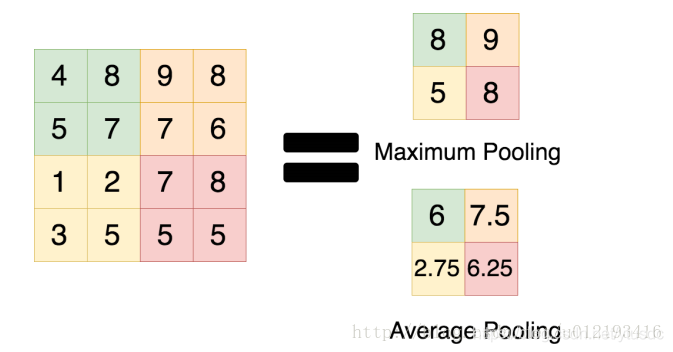 從圖中可以發現,兩者顧名思義,一個是取最大值另一個則是取平均值,雖然在過去平均池化層也曾被廣泛使用,但因最近最大池化層在實踐上的表現較好,因此現在較少被使用到。 特徵提取的誤差主要來自兩個方面: (1)鄰域大小受限造成的估計值方差增大; (2)卷積層參數誤差造成估計均值的偏移。 一般來說,average-pooling能減小第一種誤差,更多的保留圖像的背景信息,max-pooling能減小第二種誤差,更多的保留紋理信息。 average-pooling更強調對整體特徵信息進行一層下採樣,在減少參數維度的貢獻上更大一點,更多的體現在信息的完整傳遞這個維度上,在一個很大很有代表性的模型中,比如說DenseNet中的模塊之間的連接大多采用average-pooling,在減少維度的同時,更有利信息傳遞到下一個模塊進行特徵提取。 但是average-pooling在全局平均池化(global average pooling)操作中應用也比較廣,在ResNet和Inception結構中最後一層都使用了平均池化。有的時候在模型接近分類器的末端使用全局平均池化還可以代替Flatten操作,使輸入數據變成一維向量。 有興趣進一步了解的人可參考該[連結](https://paperswithcode.com/method/global-average-pooling)