【QA】卷積神經網路(CNN)的卷積層(Convolution)是如何運作的??
說到深度學習的CNN,大家想到的第一個用途肯定是影像辨識 那麼,為何要使用CNN來做影像辨識呢, 下面想以CNN中的卷積層(Convolution)來跟各位介紹,為何使用CNN以及其中的卷積層是如何運作的
回答列表
-
2021/08/14 下午 01:44Ray贊同數:0不贊同數:0留言數:0
卷積層(Convolution)的運作方式基本上是使用卷積核(Kernels)滑動對圖像做特徵提取,常見的Kernel大小有1乘1, 3乘3, 5乘5, 7乘7,之所以大多為奇數是因為奇數的卷積核有中心點,較容易對齊確認位置資訊,再者是因為奇數的卷積核能確保填充(Padding)的對稱性,而卷積核做特徵提取的方式如下圖: 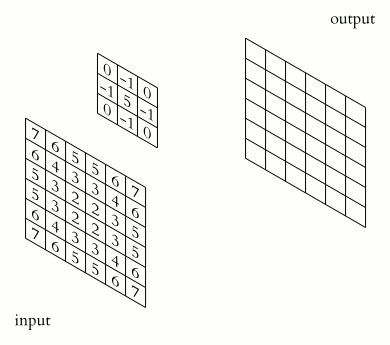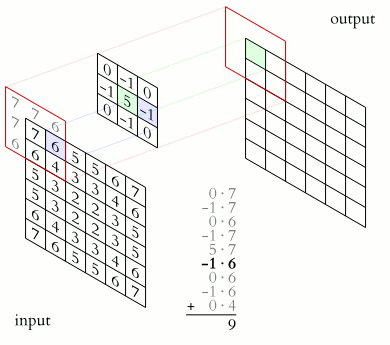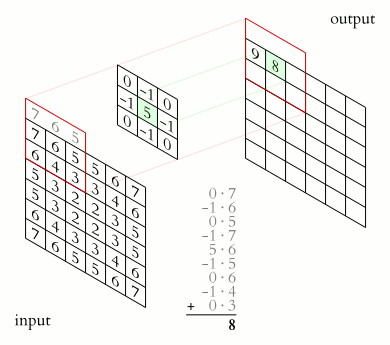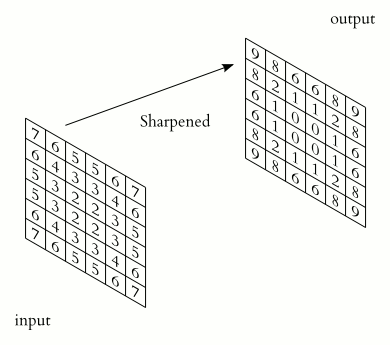 當卷積核在做特徵提取的過程中還有兩個重要的參數:步長(Strides)與填充 (Padding) 這三個參數會決定最後Feature map的輸出尺寸,Feature map的輸出尺寸計算公式如下圖: $$$$ Output=\frac{Input+2\times Padding-kernel}{stride} +1 $$$$ 步長(Strides)為控制圖像長寬尺寸的方式之一,下圖中的Kernel步長分別為1、2,可以觀察到輸出的Feature map大小也不同,雖然通常長寬上的步長會設為相等,但我們也可以透過不同的長寬步長控制Feature map不同維度尺度的變化。 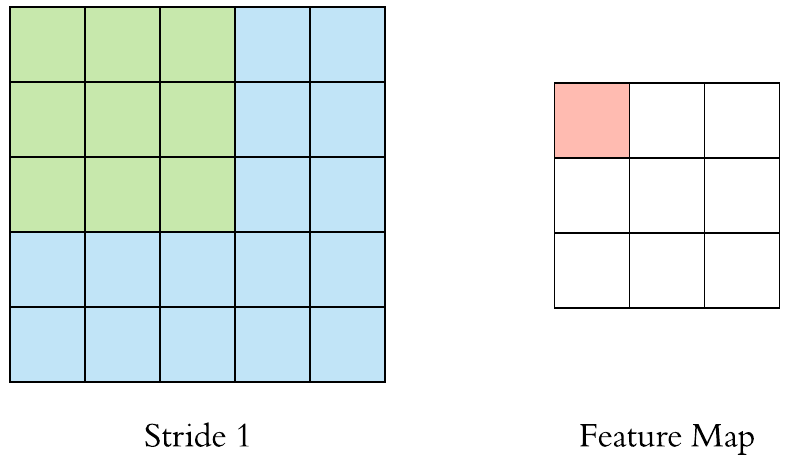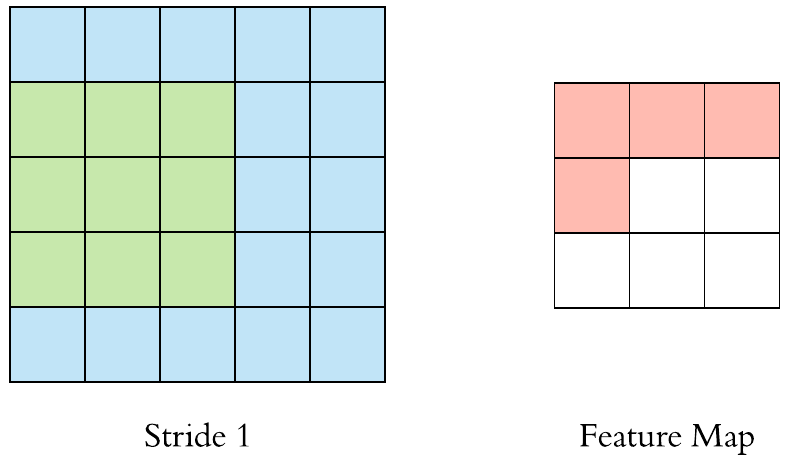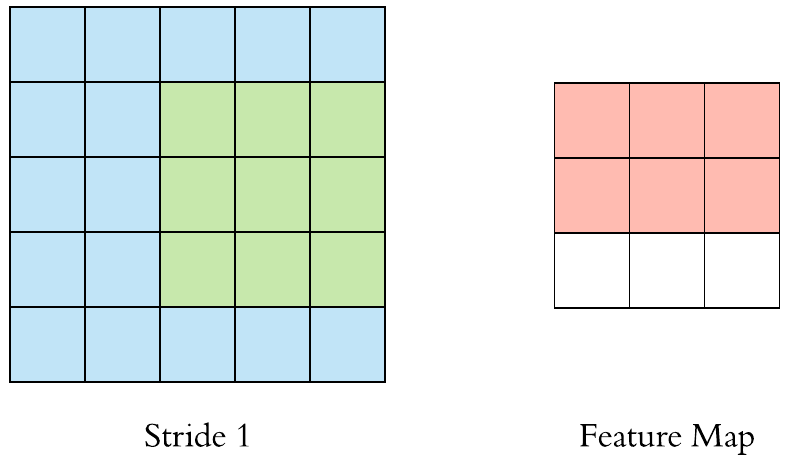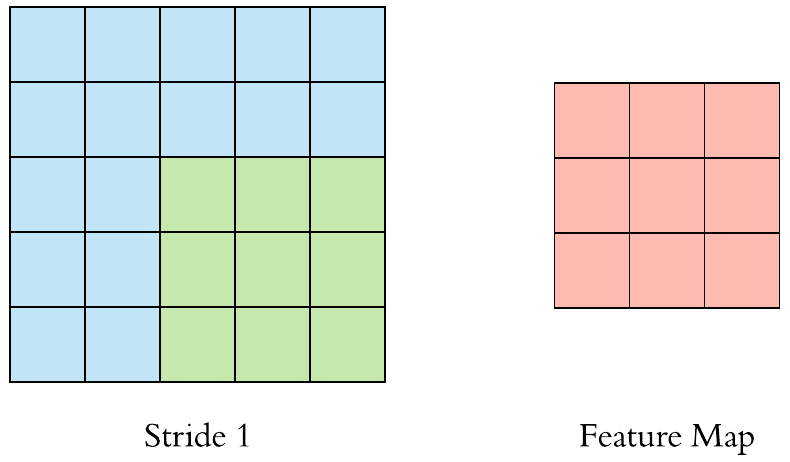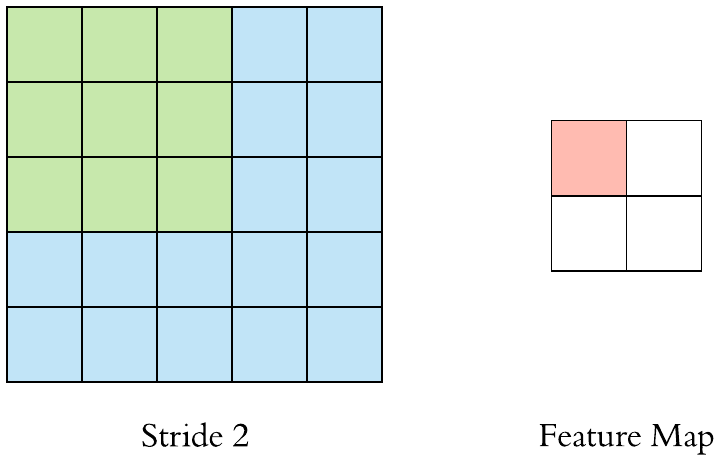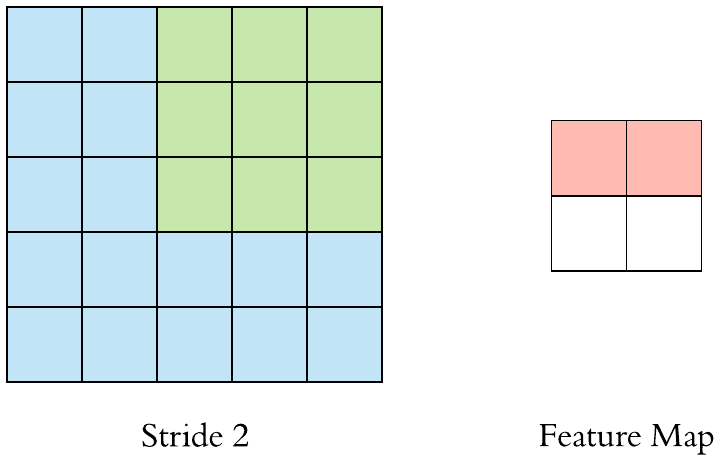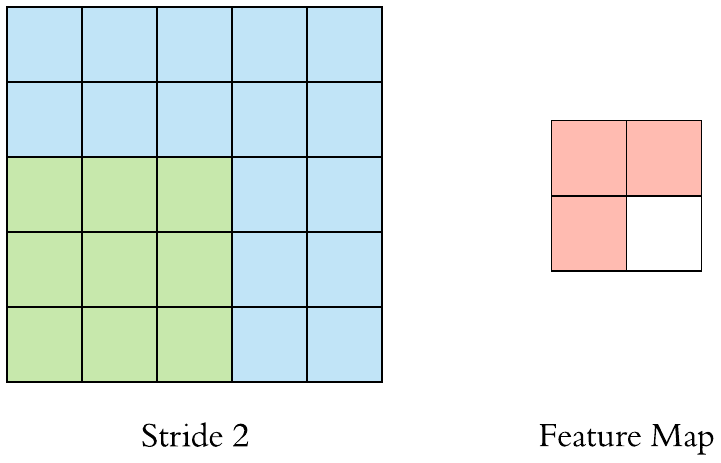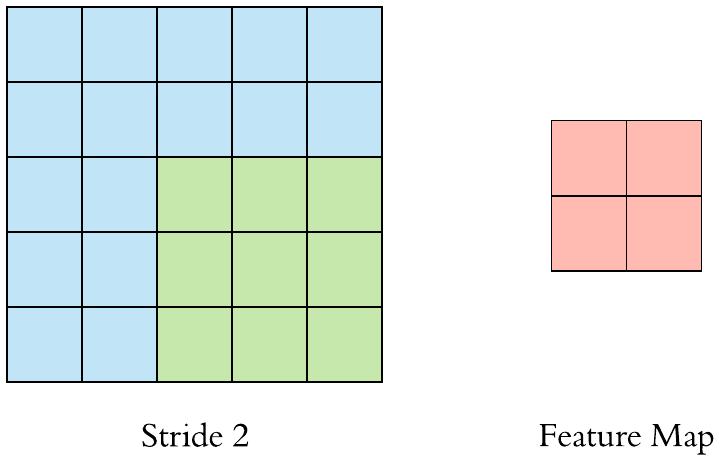 填充 (Padding)一般來說可以分為三種: Same Padding:在Stride為1時,會讓輸出Feature map與輸入圖像維持一樣的尺寸,可參考下方程式碼。而當Stride大於1時,輸出Feature map寬、高等於輸入影像寬、高/Stride(小數值無條件進位)。 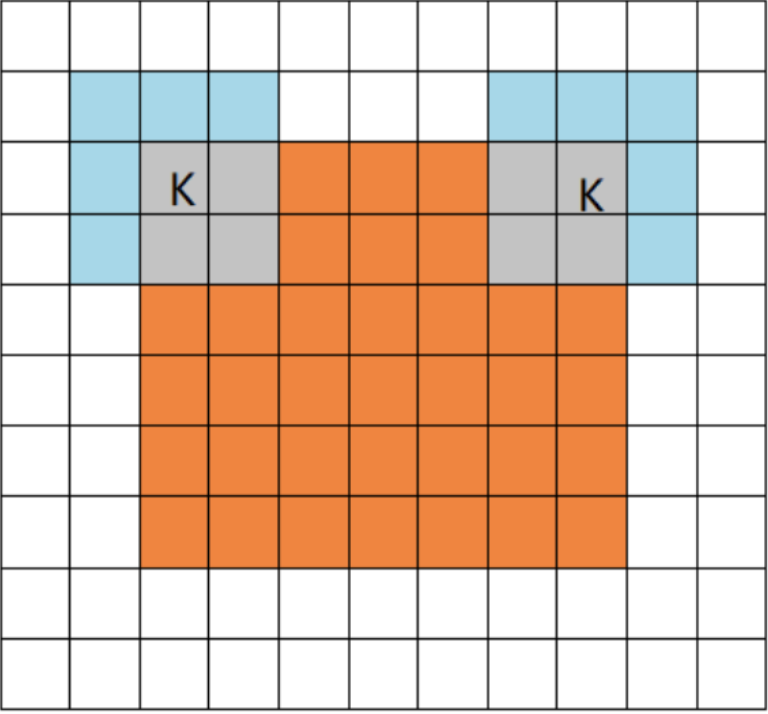 Valid Padding:當卷積核全部都在圖像內時開始卷積,不會特別去補值,因此會讓輸出的Feature map尺寸下降,而當遇到卷積無法完整卷積的狀況則會直接捨棄多出來的像素。 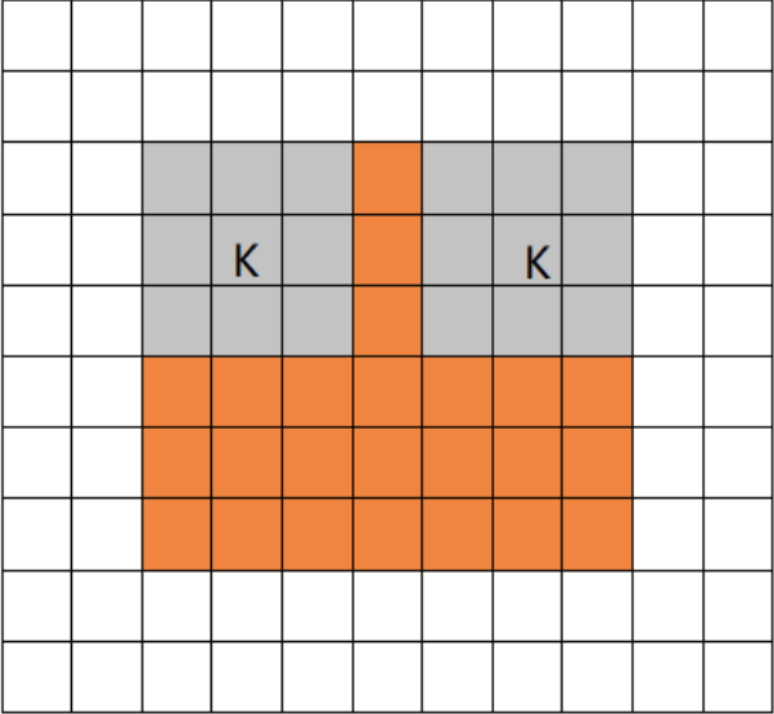 Full Padding:在卷積核與圖像一開始接觸的地方開始做卷積,而其餘非圖像部分則補值為0的像素。