【QA】什麼是自編碼(Autoencoder)?
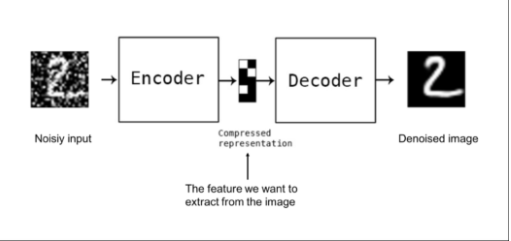
先簡單介紹一下自編碼: 自編碼,又稱為自動編碼器,是一種在深度學習的半監督式學習以及非監督式學習中使用的人工神經網路,主要是用於資料的降維以及資料特徵的擷取 自編碼是由編碼器(Encoder)和解碼器(Decoder)兩部分組成的,其功用簡而言之便是對輸入訊號進行轉換,也就是壓縮和解壓,簡單舉個例子: 自編碼神經網路input一張圖片後,將其打上馬賽克,然後在output出來 如下圖:  那麼自編碼在深度學習中具體是怎麼運作的呢? 以下想跟各位討論看看:
回答列表
-
2021/08/08 下午 08:51Ray贊同數:0不贊同數:0留言數:0
如上文所述,自編碼器中的編碼器會對輸入數據進行轉換編碼成一段code,之後解碼器在將code解碼並輸出;而其目的是讓輸入與輸出盡可能相同,沒錯,我們會希望輸入和輸出會是相同的東西,因為在使用自編碼的時候,我們不會去過度關心輸出結果,真正重要的是在輸入與輸出之間的code,其過程如下圖所示: 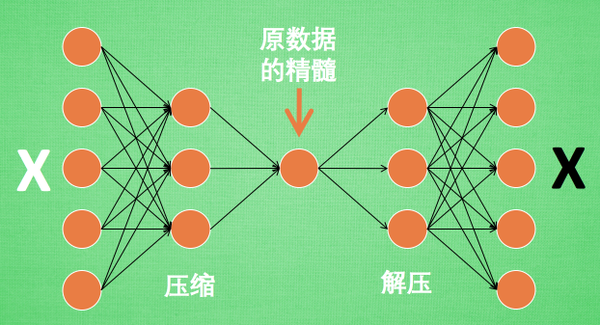 用數學來表示的話,便是將輸入x input進編碼器f得編碼y,也就是 y=f(x) 之後再將編碼y放入解碼器h中得輸出x’ x’=h(y)=h(f(x)) 此時x’趨近於x 這其實便是特徵擷取的一種方式,在這個神經網路系統中,我們會希望在輸入訊號與編碼器轉換後的code兩者不同的條件下,解碼器能夠將code還原成輸入數據,若是能夠成功還原那便說明該code已經具備原始輸入數據中所有重要的特徵資訊,從而實現讓神經網路自動學習特徵擷取,因為在剛才的過程中,我們只有使用到輸入數據,而沒有使用到與輸入數據對應的label,因此才說自編碼是一種非監督式學習 通常在使用自編碼時,只會使用到前半部分的編碼器(Encoder),因為我們需要的便是編碼器對輸入數據轉換後的code,在將輸入數據中的特徵精簡並轉換成code後,便能將其作為深度學習神經網路的輸入使用,從而減輕神經網路在學習上的負擔 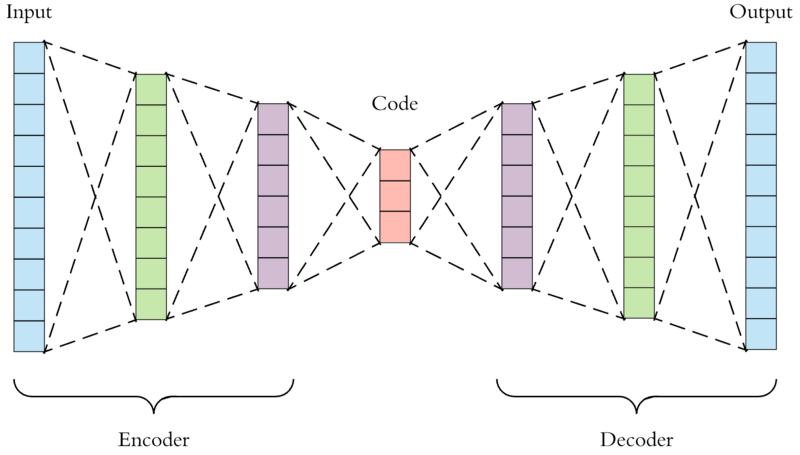[參考圖片來源](https://www.google.com/url?sa=i&url=https%3A%2F%2Fithelp.ithome.com.tw%2Fm%2Farticles%2F10212018&psig=AOvVaw0uNVmU7UjNEKUZKH6UJaQO&ust=1631374153276000&source=images&cd=vfe&ved=0CAsQjRxqFwoTCPCj77nc9PICFQAAAAAdAAAAABAD) 而解碼器(Decoder)在訓練的過程中則是將編碼後的code還原成原始數據,也就是對code進行解壓的動作,有點類似於GAN,而做這件事的特殊自編碼器稱為Variational AutoEncoders,對這部分有興趣的人可以參考該[連結](https://kvfrans.com/variational-autoencoders-explained/) 這裡介紹一下自編碼的特點: 1. 自動編碼器是資料相關的(data-specific 或 data-dependent),這意味著自動編碼器只能 壓縮那些與訓練資料類似的資料。比如,使用人臉訓練出來的自動編碼器在壓縮別的圖 片,比如樹木時效能很差,因為它學習到的特徵是與人臉相關的。 2. 自動編碼器是有損的,意思是解壓縮的輸出與原來的輸入相比是退化的,MP3,JPEG等壓縮 演算法也是如此。這與無失真壓縮演算法不同。 3. 自動編碼器是從資料樣本中自動學習的,這意味著很容易對指定類的輸入訓練出一種特定的 編碼器,而不需要完成任何新工作。 最後這邊也另外介紹一下幾種不同的自編碼器給各位認識一下: 1. 卷積自編碼器(CNN AutoEncoder):卷積自編碼器又稱CNN自編碼器,是使用卷積層來 取代原本自編碼器中的全連線層,其原理和自編碼器一樣,因此就不贅述了,有興趣進一步 了解的人可以參考該[連結](https://datawhalechina.github.io/leeml-notes/#/chapter27/chapter27?id=cnn%e8%87%aa%e5%8a%a8%e7%bc%96%e7%a0%81%e5%99%a8) 2. 稀疏自編碼器(Sparse AutoEncoder):基本上稀疏自編碼器就是在原本的自編碼器的基礎 上加上L1的Regularity限制變成為了稀疏自編碼,而L1主要是約束神經網路每一層中的各節 點大部分都要為0,只有少數能夠不為0,這是Sparse名字的來源。 3. 降噪自編碼器(Denoising AutoEncoder):降噪自編碼器跟前幾種相同,皆是在原本自編 碼器的基礎上進行一些更動,而降噪自編碼器則是在輸入數據中加入噪音(或著說雜訊)或 是直接將損壞數據作為輸入,降噪自編碼器則必須學會如何去除噪音從而預測獲得原本的輸 入數據。