【轉貼】sklearn中fit、fit_transform、transform的區別
1 前言 在使用sklearn處理資料的時候,會經常看到fit_tranform(),但是偶爾也會遇到fit()和transform()函式,以下作一個簡單的整理: 2 理解 fit:原義指的是安裝、使適合的意思,其實有點train的含義但是和train不同的是,它並不是一個訓練的過程,而是一個適配的過程,過程都是定死的,最後只是得到了一個統一的轉換的規則模型。 transform:是將資料進行轉換,比如資料的歸一化和標準化,將測試資料按照訓練資料同樣的模型進行轉換,得到特徵向量。 fit_transform:可以看做是fit和transform的結合,如果訓練階段使用fit_transform,則在測試階段只需要對測試樣本進行transform就行了。 下面來看一下這兩個函式的API以及引數含義: 1、fit_transform()函式  即fit_transform()的作用就是先訓練,找到轉換資料的規則,然後根據找到的規則轉換資料。 2、transform()函式 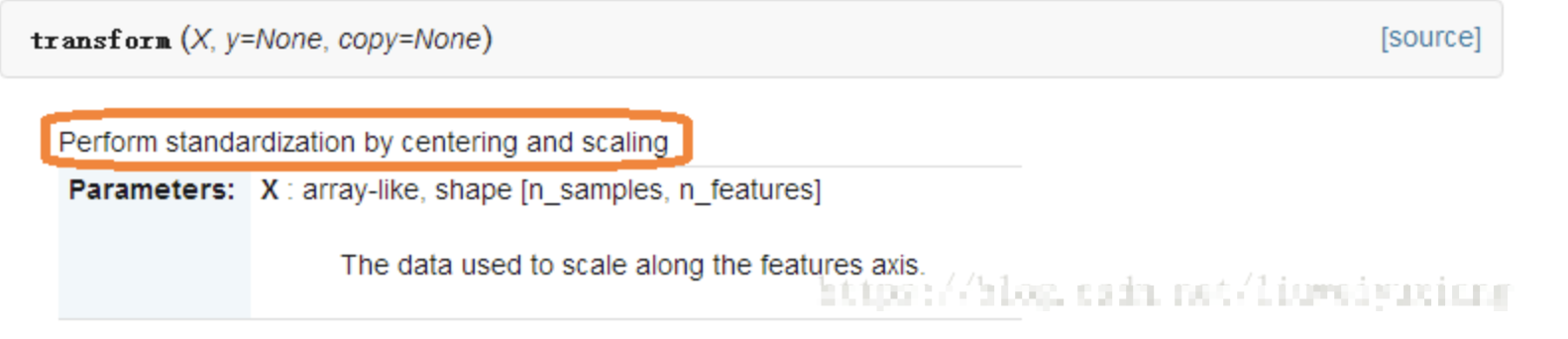 即tranform()的作用是根據找到的規則對資料進行轉換,通過找中心和縮放等實現標准化。 到了這裡,我們似乎知道了兩者的一些差別,就像名字上的不同,前者多了一個fit數據的步驟,那為什麼在標准化數據的時候不使用fit_transform()函數呢? 原因如下: 為了數據歸一化(使特徵數據方差為1,均值為0),我們需要計算特徵數據的均值μ和方差σ^2,再使用下面的公式進行歸一化: 我們在訓練集上調用fit_transform(),其實找到了均值μ和方差σ^2,即我們已經找到了轉換規則,我們把這個規則利用在訓練集上,同樣,我們可以直接將其運用到測試集上(甚至交叉驗證集),所以在測試集上的處理,我們只需要標准化數據(transform)而不需要再次擬合數據(fit)。用一幅圖展示如下: 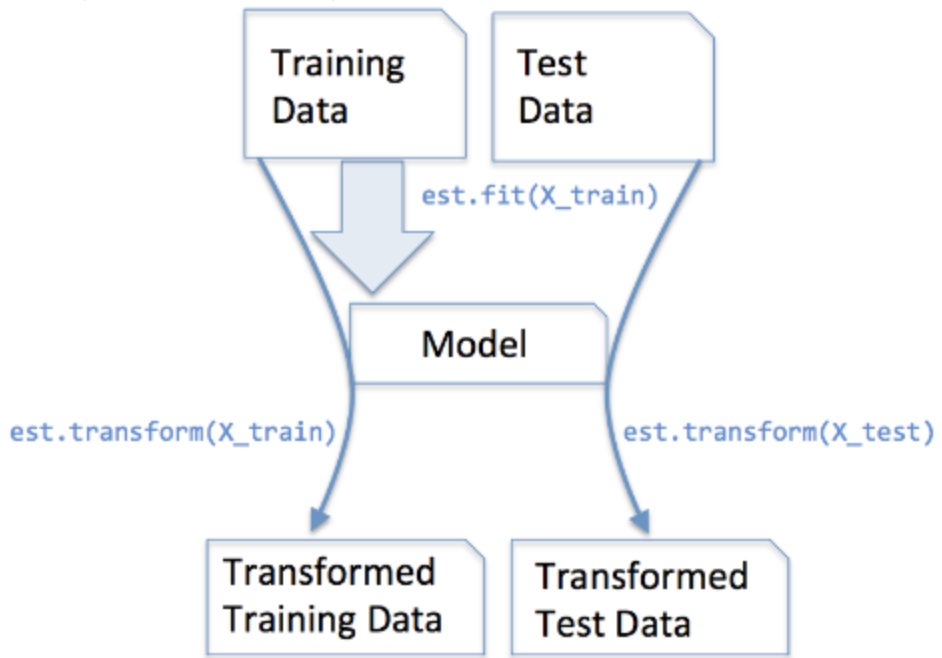 說明: - est.fit(X_train) : 使用Training Data建立Model - est.transform(*) : 利用該Model產生Transformed data ———————————————— 原文網址:https://blog.csdn.net/quiet_girl/article/details/72517053